📖 Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens
Jiacheng Liu1, Sewon Min1, Luke Zettlemoyer1, Yejin Choi1,2, Hannaneh Hajishirzi1,2
1University of Washington, 2Allen Institute for AI
[Web Interface] [API Endpoint] [Python Package] [Docs] [Code] [Paper]
[✨NEW] Check out infini-gram mini, a more storage-efficient index based on FM-index, with similar functionalities as infini-gram.
[✨NEW] Check out OLMoTrace, an LLM behavior tracing tool we developed on top of infini-gram.
Join our Discord server! Get the latest updates & maintenance announcements, ask the developer anything about infini-gram, and connect with other fellow users.
It’s year 2024, and n-gram LMs are making a comeback!!
We built an n-gram LM with the union of several open text corpora: {Dolma, RedPajama, Pile, and C4}. The “n” in this n-gram LM can be arbitrarily large. This model is trained on 5 trillion tokens, and contains n-gram counts for about 5 quadrillion (or 5 thousand trillion, or 5x10^15) unique n-grams. It is the biggest n-gram LM ever built to date.
Infini-gram is an engine that efficiently processes n-gram queries with unbounded n and trillion-token massive corpora. It takes merely 20 milliseconds to count an arbitrarily long n-gram in RedPajama (1.4T tokens), while also retrieving all of its occurrence positions in the corpus.
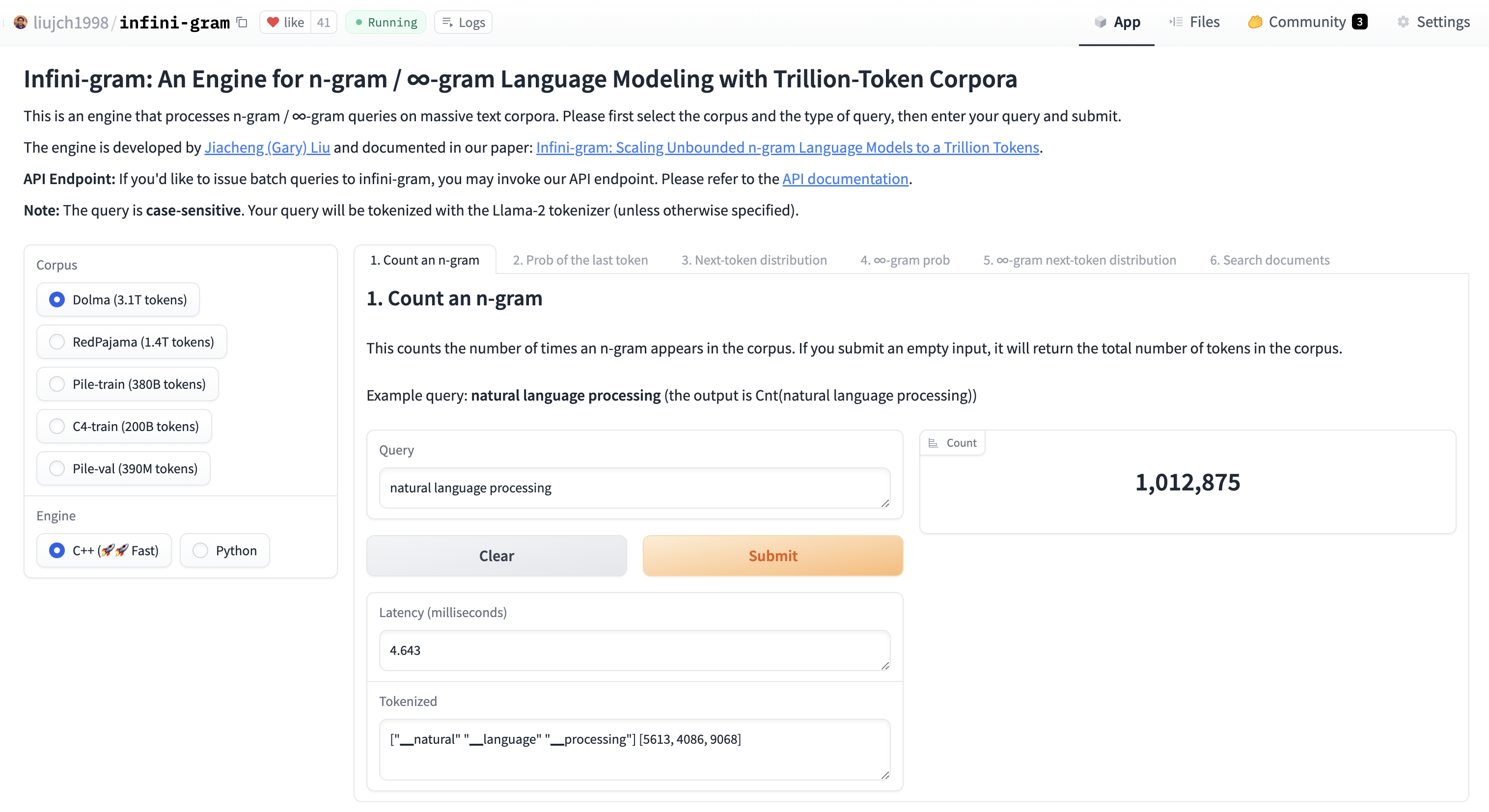
Beyond counting n-grams, infini-gram offers more functionalities. You can compute n-gram LM probabilities and next-token distributions, which can be handy for text decoding. You can also search for documents that contain an n-gram term, one of multiple n-gram terms, all of multiple n-gram terms, or a combination of these (see CNF expressions). To explore these functionalities, check out our web interface.
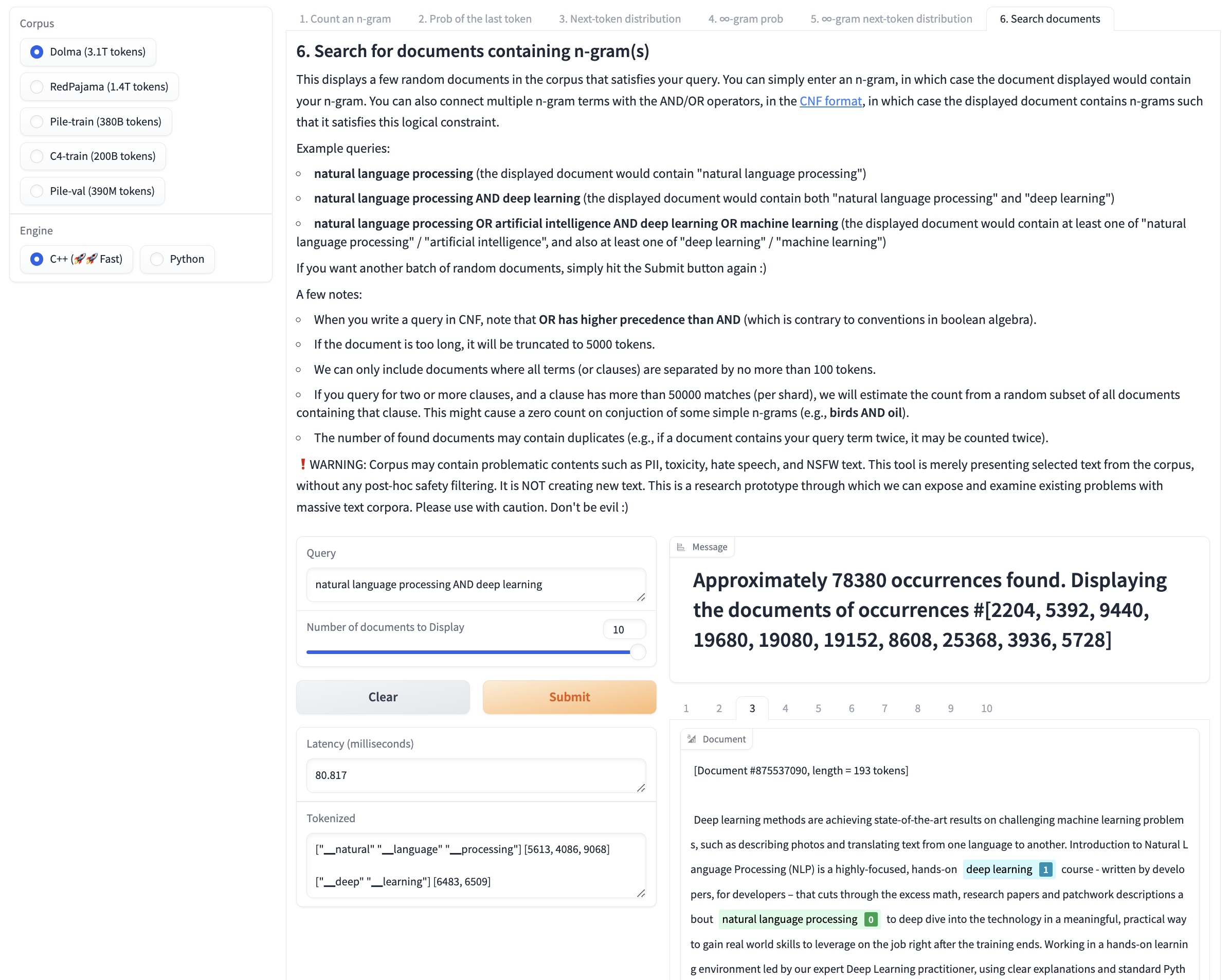
If you’d like to explore infini-gram or use in small volume, please check out our web interface. If you’d like to programmatically query infini-gram, we offer a free and easy-to-use API endpoint, please check out the API documentation.
What can I use infini-gram for?
In our paper, we use infini-gram to analyze text, both human-written and machine-generated. We also use infini-gram for language modeling: the ∞-gram LM, which is powered by infini-gram, can complement neural LMs and greatly reduce their perplexity.
We are very excited that infini-gram is being actively used by our fellow research groups in these areas:
- Memorization
- Membership inference
- Text generation
- Document retrieval
- Dataset curation
- Copyright protection
Beyond these, we envision that infini-gram can be useful in many other applications, such as:
- Understanding text corpora
- Attribution
- Detecting data contamination and plagiarism
- Reducing hallucination
- Speculative decoding
- Offloading rote memorization from neural models
Below we show a few results from our paper, which uses infini-gram for text analysis and language modeling.
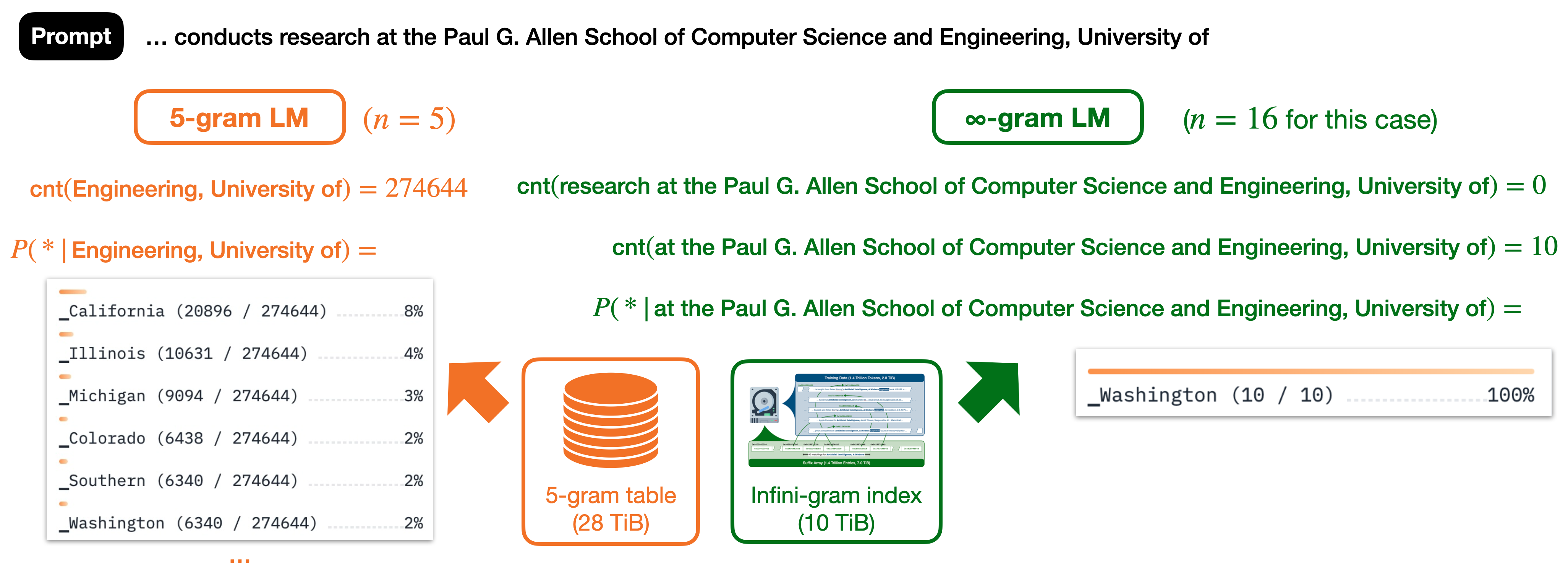
Why do we need unbounded n?
Using larger n improves the predictive power of n-gram LMs. Existing n-gram LMs are mostly built with n<=5, which limits their capability to predict the next token (shown in image below). If we increase to n=16, we still get a non-zero n-gram count in RedPajama, but now the model makes a correct prediction. This is why we generalize n-gram LMs to unbounded n, i.e., an ∞-gram LM. ∞-gram uses the longest context possible (right before the count becomes zero), and our infini-gram engine perfectly supports this.
Analyzing human-written text
Using the ∞-gram framework and infini-gram engine, we gain new insights into human-written and machine-generated text.
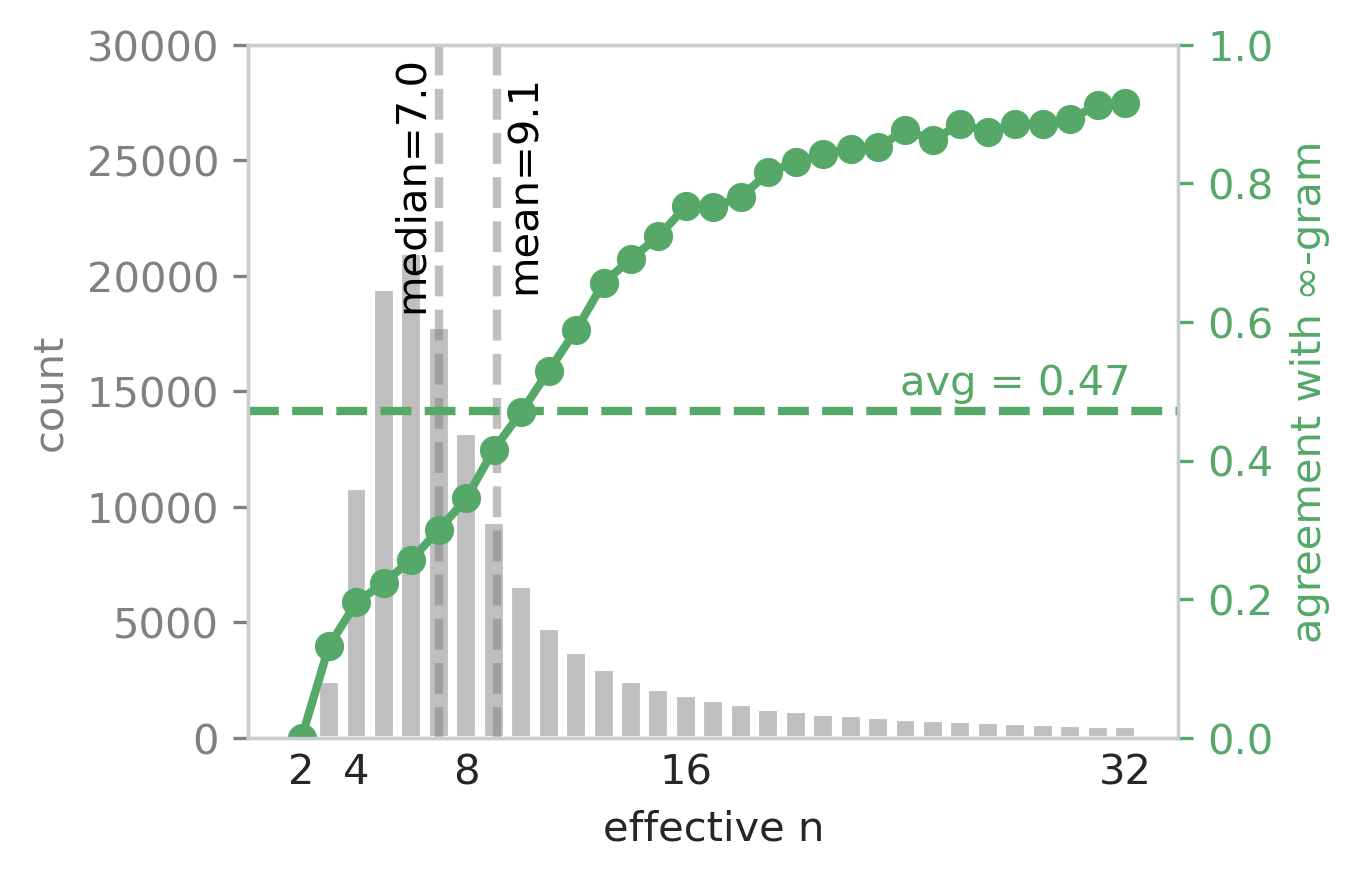
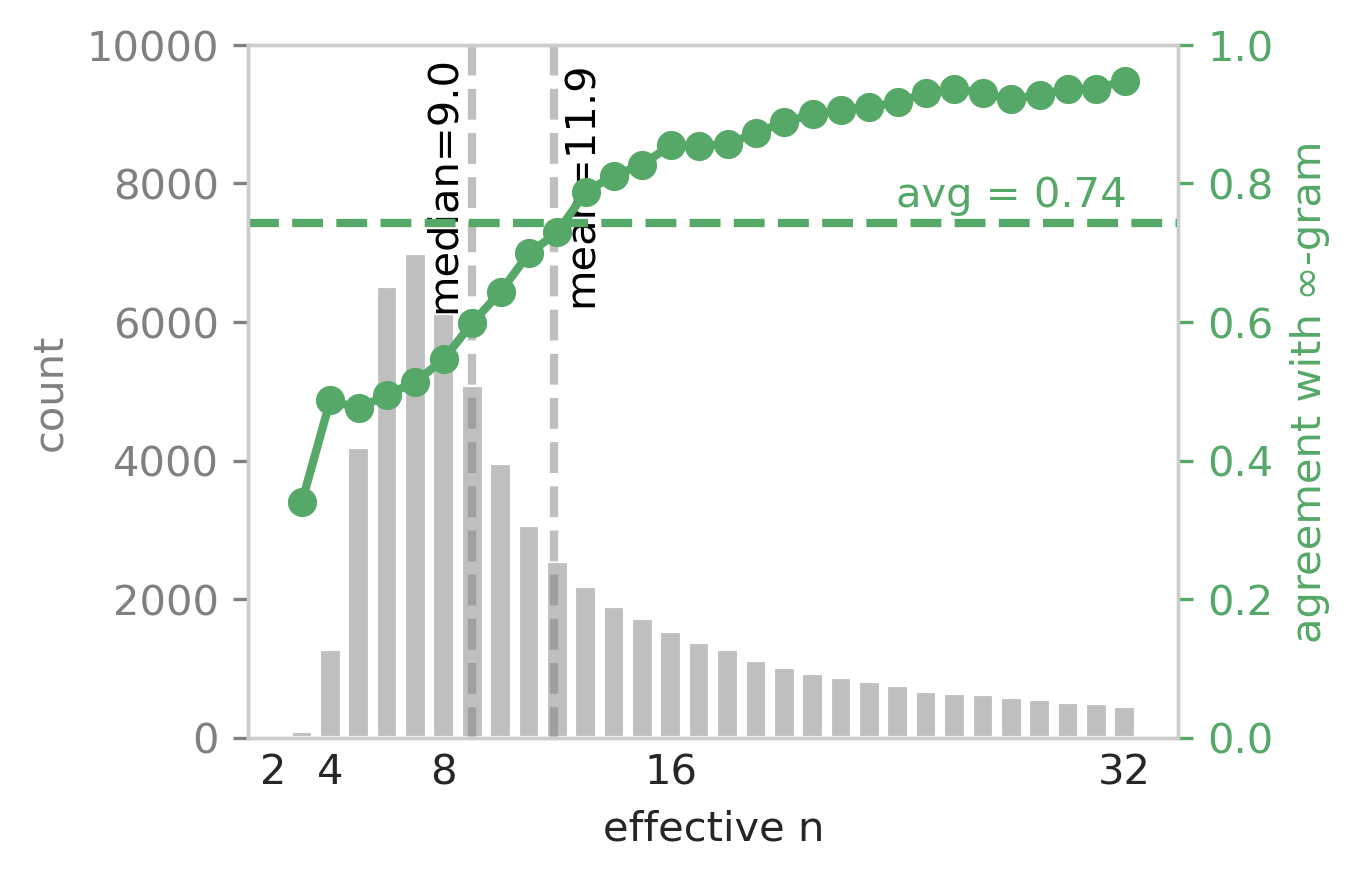
∞-gram is predictive of human-written text on 47% of all tokens, and this is a lot higher than 5-gram (29%). This prediction accuracy is much higher among tokens that can use a larger n (left image), and is also higher when the ∞-gram estimate is sparse (right image).
Interpolating ∞-gram LM with neural LMs
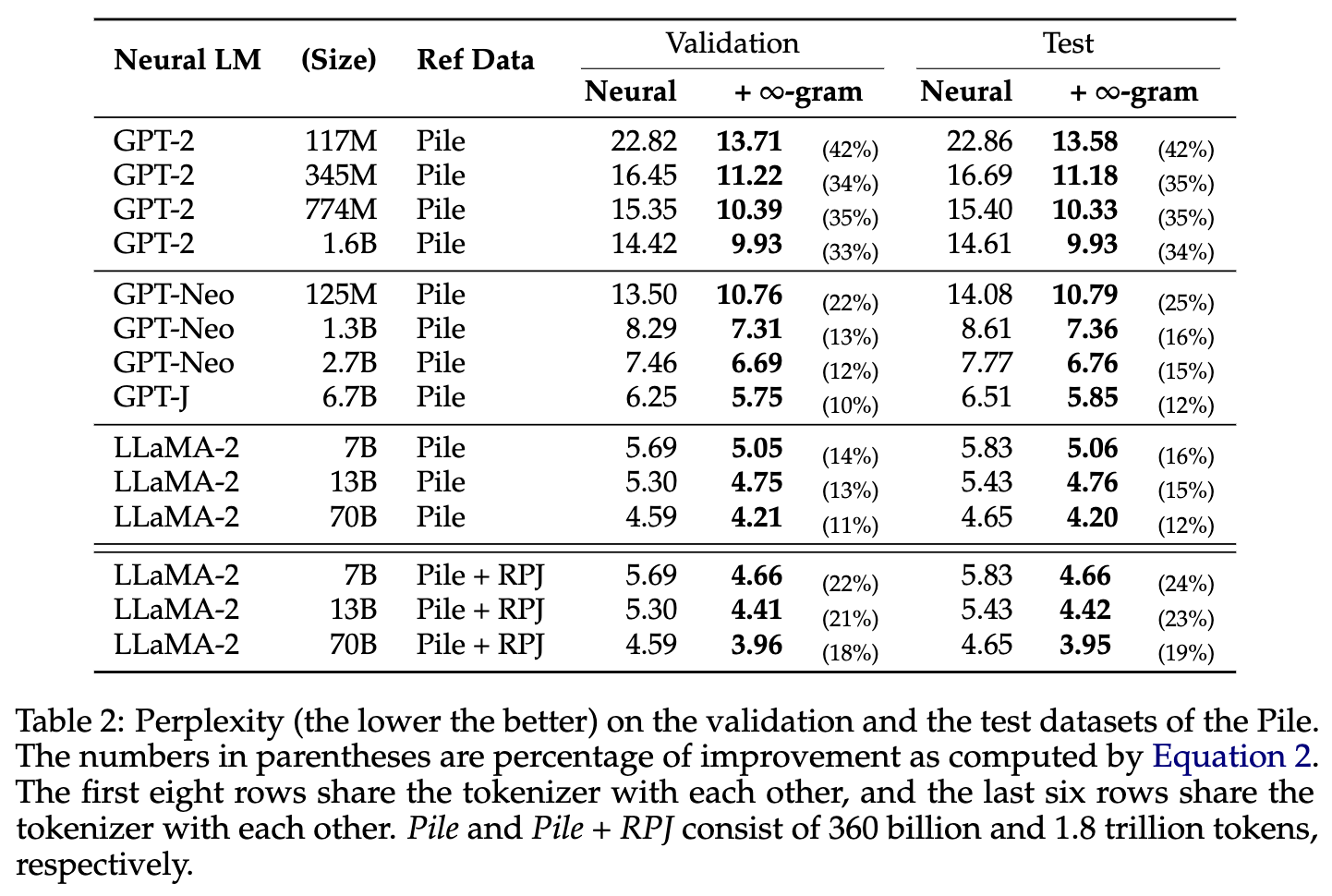
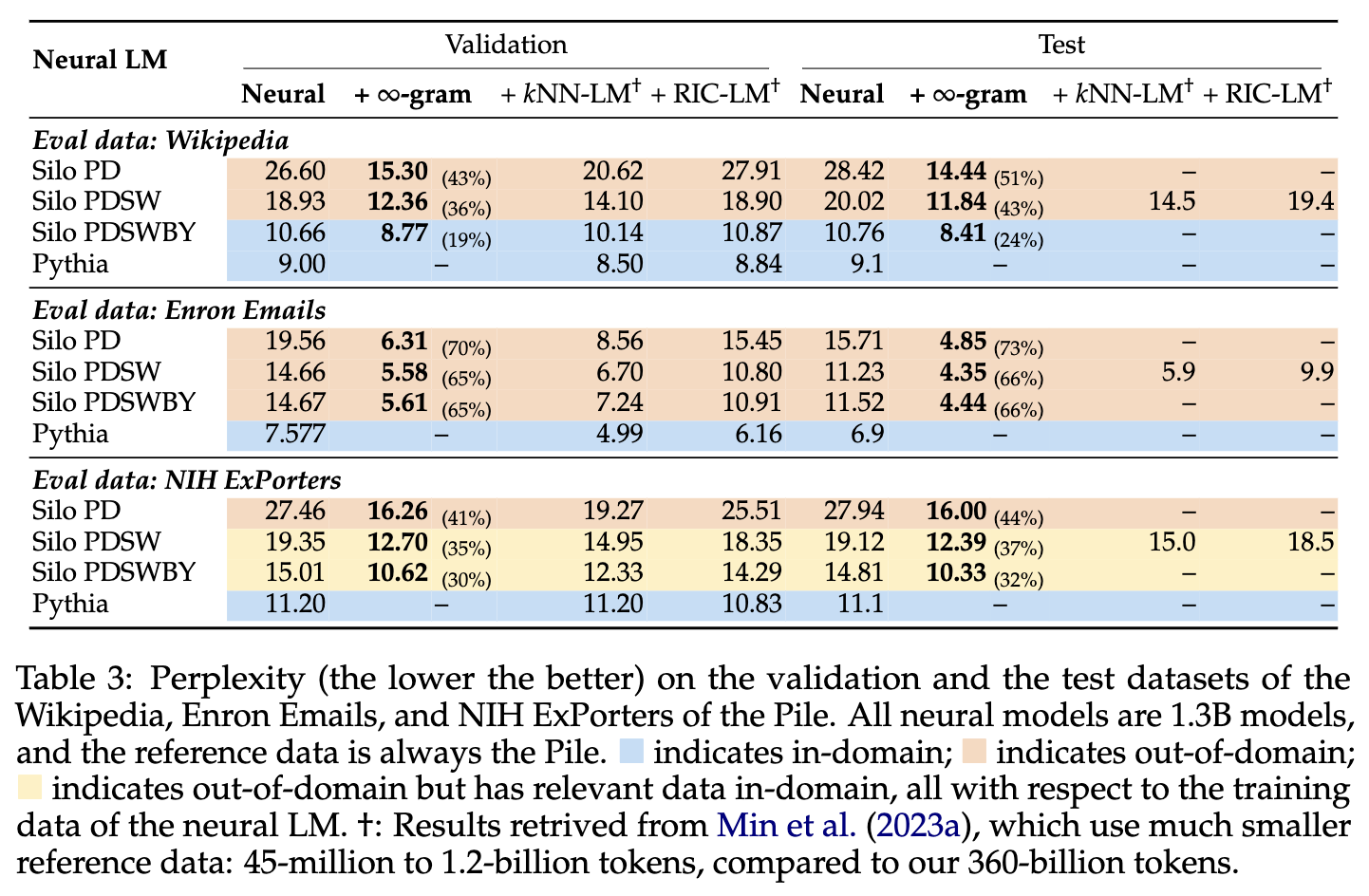
Interpolating with ∞-gram reduces the perplexity of neural LLMs by up to 73%, and this works even when the neural LLM is Llama-2-70B! ∞-gram also outperforms kNN-LM and RIC-LM as retrieval-augmentation strategy used by the SILO model (Min et al., 2023).
What's happening behind the infini-gram engine?
The infini-gram index is a data structure called “suffix array”, which stores the ranking of all suffixes of a byte array. In our use case, the byte array is the concatenation of all (tokenized) documents in the corpora.
Here’s an illustration of how suffix array works:
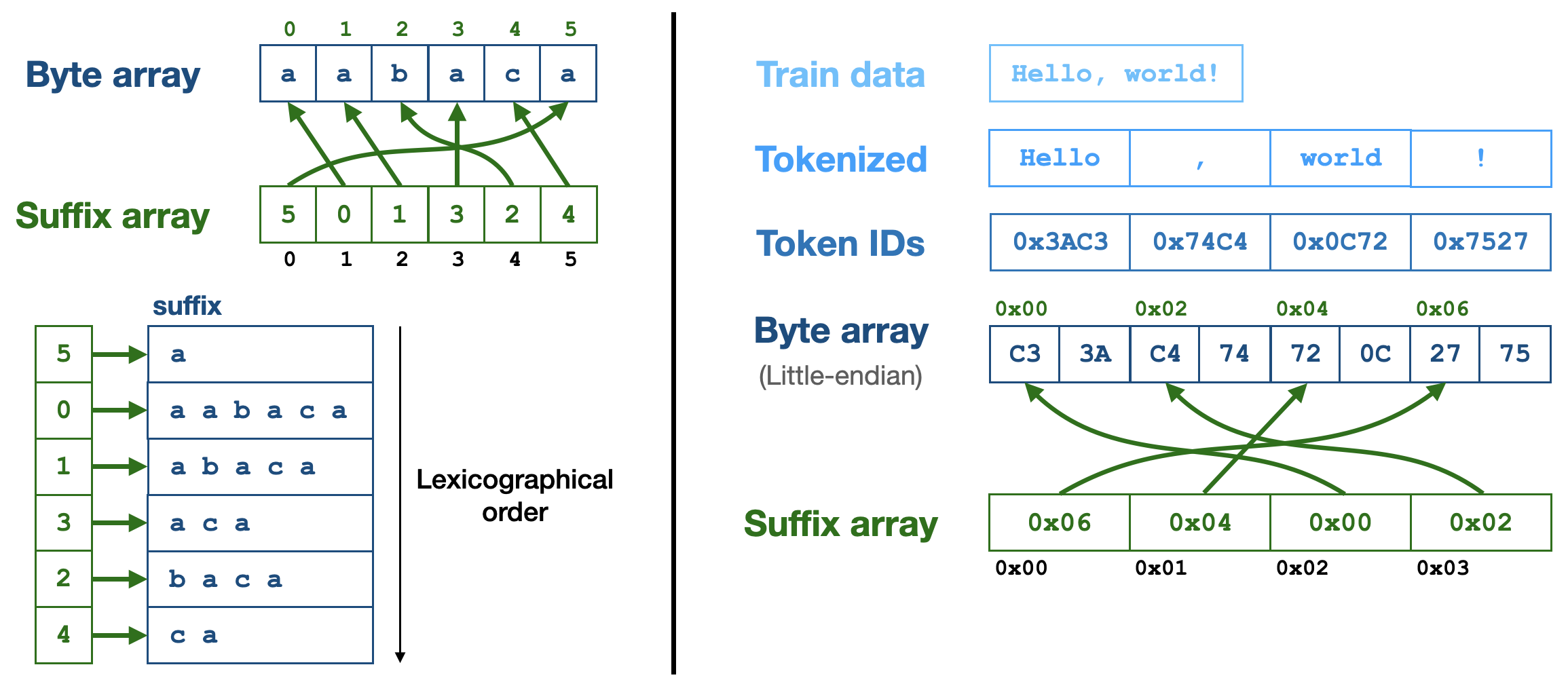
Here’s an illustration of the suffix array for a trillion-token corpus:
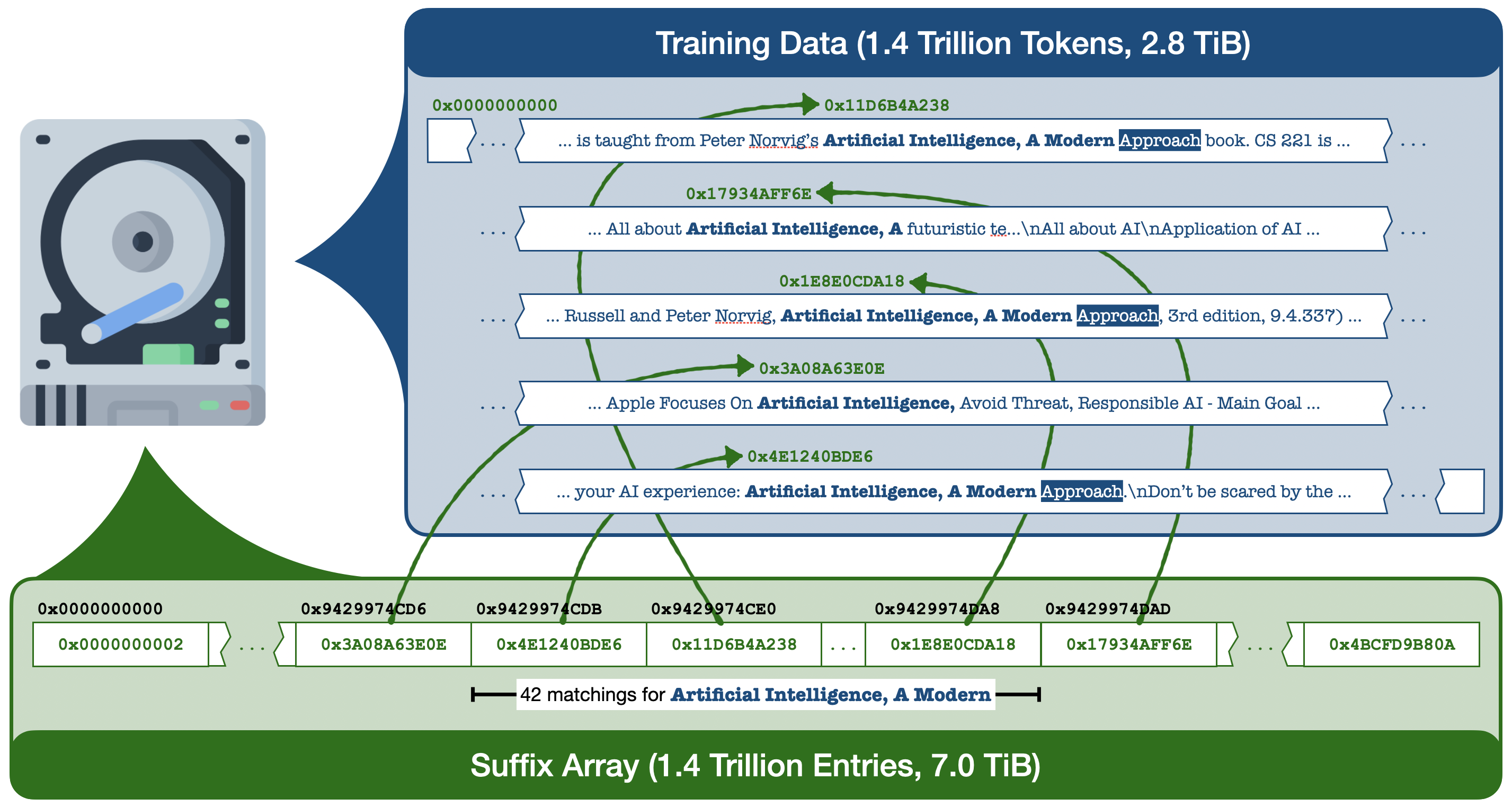
The suffix array occupies O(N) space and can be built in O(N) time.
Inference is lightning fast! On RedPajama, n-gram counting is 20 milliseconds (regardless how large n is); n-gram LM probability estimation and decoding is within 40 milliseconds per query. ∞-gram takes a bit longer (because it needs to figure out the longest n), but still under 200 milliseconds per query.
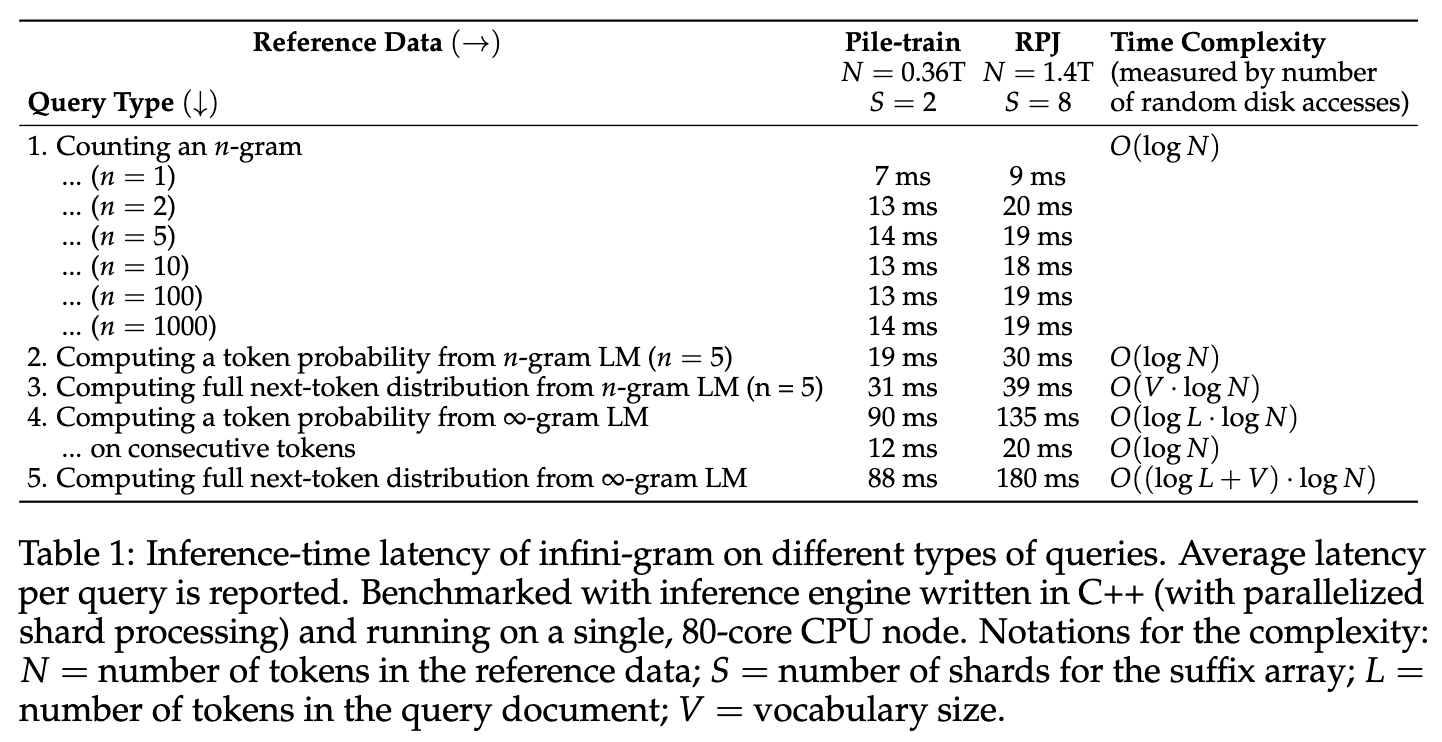
Also, inference requires very little compute (CPU, RAM), since the index can stay on disk. And above all, infini-gram requires 0 GPU for both training and inference!! 🙈🙈
Citation
If you find infini-gram useful, please kindly cite our paper:
@article{Liu2024InfiniGram,
title={Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens},
author={Liu, Jiacheng and Min, Sewon and Zettlemoyer, Luke and Choi, Yejin and Hajishirzi, Hannaneh},
journal={arXiv preprint arXiv:2401.17377},
year={2024}
}